¶ Random이란?
- "닥치는 대로의", "무작위의"
- 자연 현상에서 가져온다면 random
- 컴퓨터가 뽑아내면 pseudo-random
¶ Pseudo-random
- 하드웨어 기반의 RNG(random number generator)를 이용할 수도 있지만 비싸고 느림


¶ PRNG
- 완전히 random한 seed값 하나만 이용해서 로직에 따라 일련의 값을 생성하는 방식
- Java는 2020년까지 선형 합동 생성기(Linear Congruential Generator) 알고리즘을 이용
- mod 연산에 의존
- Java 17부터는 다양한 생성기 알고리즘이 제공되며 커스터마이즈도 가능함
¶ LCG
¶ Random의 특성
- 예측하기는 어렵지만 분포가 균질하진 않음
- 중복이 발생하거나 특정 값 인근에서 몰려서 발생하기도 함
- 반대로 확률적으로 예측되는 값이 발생하지 않기도 함
- 주사위를 60번 던져도 1이 한 번도 안 나올 수 있음
¶ Uniform distribution
- 주사위를 60번 던졌는데 주사위 눈이 각각 10번씩 나오는 분포
- 이렇게 예측이 가능하다면 게임을 할 수 있나?
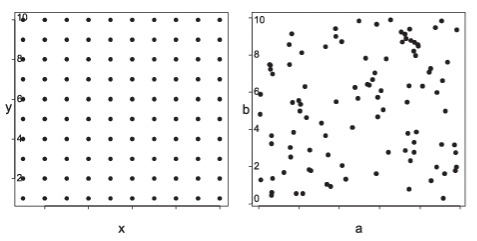
¶ 분포의 비교
- uniform vs normal
- uniform vs random in 2 dimension
- 언제 어떤 분포를 사용하는 게 필요한가?
- random은 예측이 어렵게 만들 때
- uniform은 공평한 분배가 필요할 때
- normal은 인구적 특성을 따라야 할 때
¶ 원주율 계산을 해보자

¶ "Monte-Carlo" 방법에 의한 원주율 계산 시뮬레이션
- 랜덤하게 좌표를 구한 다음, 좌표 (0, 0)으로부터의 거리를 구해서
- 반지름 이내에 들어온 갯수를 세고 ... n1
- 반지름 바깥에 들어온 갯수를 세어 ... n2
- 그 비율을 계산하면 원주율을 구할 수 있음
- 오차가 상당히 큼
- 수천 번에서 수만 번을 시도해도 3.0이나 3.2 정도의 값이 나오기도 함
- 3.14에 가까운 값을 얻으려면 수십만 번 시도해야 함
- 오차의 발생원인?
- random "bias"
¶ 중간적 성질을 가지는 random 분포
"Equi-distribution"
"quasi-random"
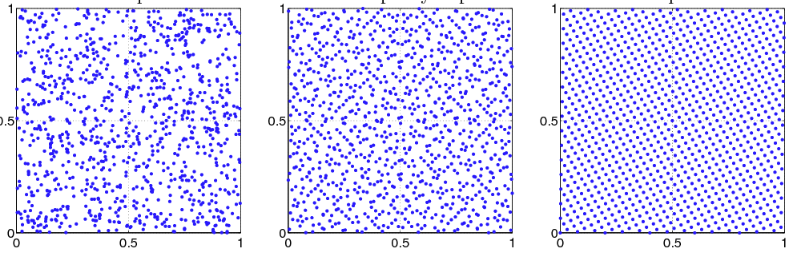
¶ 구체적인 수열 생성 방법
- Halton
- Sobol
- van der Corput
- R2
¶ 1차원에서
¶ van der Corput 수열
- quasi-random한 random number sequence

- 계산 방식이 간단해서 컴퓨팅에서 많이 응용함
- 분산 클러스터의 각 노드에 quasi-random으로 균등 분배할 때 편리함
- 이 수열 사용 시, 클러스터 구성에 변경이 생겨도 재계산 불필요
¶ 다차원에서
¶ R-sequence 알고리즘
- 알파는 무리수
- n = 1, 2, 3, ...
- { x }는 x의 소수점 이하 값
- s0는 seed 값
알파값으로 원주율을, s0값으로 0을 사용하게 되면, 수열은 다음과 같은 형태가 됨
0.618, 0.236, 0.854, 0.472, 0.090, 0.708, 0.327, 0.944, 0.562, 0.180, 0.798, 0.416, 0.034, 0.652, 0.271, 0.888, ...
¶ 품질 평가 기준
- "낮은 불일치"(low discrepancy)라는 수학적 개념이 있음
- 중복되지 않고 몰리지 않음
- 모든 quasi-random 수열의 품질 기준은 원소들 사이의 거리가 고르게 멀어야 함
- van der corput은 최대 범위가 커질수록 품질이 선형으로 좋아지는 특성이 있음
- 다양한 수열들의 lower bound 기준이 됨
¶ R2
- R1 수열을 2개 사용하면 됨
- quasi-random에서 가장 널리 사용되는 Sobol이나 Halton, Kronecker에 비해서 월등히 품질이 좋음

¶ R-sequence 알고리즘 평가
- 품질
- s0는 품질에 영향을 끼치지 않으나 자유도를 부여할 수 있음
- 알파는 품질에 영향을 끼치는데, 황금비(golden ratio, 1.6180339...)의 역수일 때 가장 품질이 높음
- R1의 품질은 van der corput보다 더 좋음
- R2의 품질은 다른 알고리즘에 비해 월등히 뛰어남
- 계산 방법이 크게 복잡하지 않아서 컴퓨팅에서 활용하기 좋음
¶ Random의 (주의해야 할) 응용 - Shuffling


- 로직
- 단순히 random mod 7로 반복해서 뽑으면 안 됨
- 한 번 랜덤하게 뽑은 것은 별도 집합에 추가하고 대상 집합의 크기를 하나씩 줄여나가야 함
¶ Fisher-Yates algorithm

¶ Random의 (잘못된) 응용 - Unique ID 발급
- Unique ID 발급에는 중복 방지가 상당히 중요함
- random 대신에 key가 되는 값이 deterministic하게 결정되는 hashing을 이용할 것
- 100% 중복 방지가 되는 건 아니지만 확률적으로 극히 낮음
¶ 소프트웨어 개발자의 주의사항
¶ in Java
- 간단한 random이 필요하면 Math.random()을 쓰자
- 정교한 random이 필요하면 java.util.Random을 쓰자
- thread-safe하지만 동시에 사용하면 느려짐
- 대신 ThreadLocalRandom을 쓰자
- 스트림에서 쓰려면 SplittableRandom을 쓰자
- 암호학적으로 안전한 random이 필요하면, SecureRandom을 쓰자
¶ in Linux
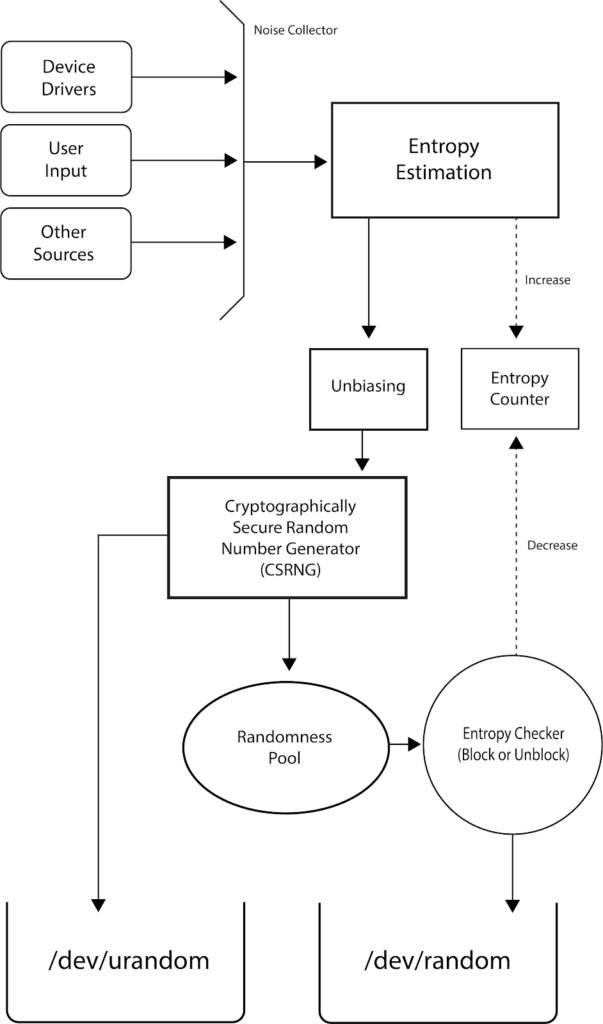
- 엔트로피를 '추정'만 함. 계산을 반복적으로 하진 않음
- /dev/random vs /dev/urandom
- blocking IO vs non-blocking IO
- 엔트로피가 낮아지면 /dev/random은 block됨 (안전함)
- /dev/urandom은 block이 안 됨(취약함)
- 중간 수준의 /dev/arandom이라는 것도 있음
¶ 공통
- 꼭 random을 써야 하는지 다시 생각해보자
- 혹시 quasi-random이 필요한 경우가 아닌가?
- 자주 중복되거나 값들끼리 몰려도 괜찮나?
- random을 사용할 때 암호학적으로 안전해야 하는지 생각해보자