¶ 모니터링 시계열 지표의 타입
Prometheus/OpenTelemetry 생태계에서 수집되는 모니터링 시계열 지표의 타입에는 크게 게이지(gauge), 카운터(counter), 히스토그램(histogram), 서머리(분포) 등이 있다.
¶ 카운터 타입
이 중에서 게이지 타입 지표는 특정 순간의 지표의 측정값이라서 그냥 사용하면 되는데, 카운터 타입 지표는 수집 주기를 섬세하게 고려해서 그 변화량이나 변화율을 추적해야 하는 어려움이 있다.
카운터 타입은 단조증가하기 때문에, 이전에 수집한 지표값과 같거나 증가할 뿐, 리셋을 하지 않는 이상 줄어들지 않는 특성을 가진다. 그래서 그냥 시각화를 하면 다음과 같은 형태로 나타난다.

¶ 변화율
디스크 IO나 네트웍 트래픽과 유사한 지표는 카운터 타입으로 정해지기 때문에 단조증가하는 값 자체보다는 변화량이나 변화율을 추적하는 게 더 중요하다. 단위 시간에 얼마나 많은 양이 유입/유출되었는지를 계산할 수 있어야 의미있는 모니터링이라고 할 수 있다.
¶ 순간 변화율 irate()
irate는 instant rate의 약어임
보통 순간 변화율은 두 인접 데이터 포인트의 지표값의 차이를 시간으로 나눈 것인데 irate() 함수를 사용하면 이런 계산을 간단하게 처리해준다.
irate(http_server_requests_seconds_count[20s])
20초 구간을 지정하여 10초마다 수집한 최근 데이터 포인트 2개를 사용함
30초 구간을 지정하면 첫번째 데이터 포인트를 버리고 최근 데이터 포인트 2개를 사용함

20초 시점에서 변화율이 가장 높고, 70초 시점에서 변화율이 가장 낮은 것을 알 수 있다.
선으로 이어보면 다음과 같은 라인 차트가 만들어진다.

¶ 평균 변화율 rate()
rate(http_server_requests_seconds_count[40s])
40초 구간을 지정하여 10초마다 수집된 데이터 포인트 4개(가 형성하는 10초 구간 3개)를 사용함
초반에는 데이터 포인트의 갯수가 모자를 수 있는데 데이터 포인트를 그만큼 적게 사용함

위 지표값을 rate() 함수를 이용하여 시각화하면 다음과 같이 된다.

¶ irate() vs rate()

보라색 irate() 차트가 더 뾰족한 것을 알 수 있다. 이렇게 뾰족한 것을 spike, 움푹 들어간 것을 dip이라고 부르는데, IO와 관련된 지표에서 spike를 감지하는 것은 중요한 모니터링 이벤트이므로 일반적으로는 irate()가 더 좋은 결과를 내고 spike를 감지하는 게 더 용이하다고 오해할 수 있다. 아래에서 좀 더 자세히 다뤄보도록 하겠다.
rate() 함수에는 40초 구간이 사용되고 irate() 함수에는 20초 구간이 사용되고 있는데, 단순히 시간 구간만 차이가 있을 뿐, 동일한 게 아니냐고 오해할 수도 있다. 그러나 시간 구간을 동일하게 잡더라도 irate()는 가장 마지막(최근) 데이터 포인트를 두 개 사용할 뿐이고, rate()는 구간의 첫번째 데이터 포인트와 마지막 데이터 포인트를 사용하는 것이라서 서로 다른 결과를 보여준다.
각 변화율 함수의 용도에 맞게 선택하는 것이 중요하다.
- 순간 변화율이 중요하면 irate()
- 평균 변화율이 중요하면 rate()
순간 변화율이 더 적절한지 평균 변화율이 더 적절한지 잘 모르겠다면, rate()를 추천한다.
다음 내용에서 irate()가 가지는 문제점을 살펴보고 rate()의 사용을 고려해보면 좋겠다.
¶ irate()의 문제점
¶ spike가 존재할 수도 있는 데이터 포인트가 버려지는 문제점
irate()는 spike를 잡아내지 못하는 문제점이 있다.
위의 irate() vs rate() 단락에서 spike를 감지하기 위해 irate()를 선호하는 경향이 있다고 언급했는데, 이것은 모순이 아닌가? 아니다. irate()조차 정교하게 설정되지 않으면 spike를 잡아내진 못하는 한계점이 있다는 의미이다. 이것에 대해 자세히 살펴보자.
각 함수에 사용하는 시간 구간을 정교하게 잡으면 spike를 감지할 수 있지만, 보통 시간 구간 내의 데이터 포인트가 2개보다 많기 때문에 오래된 데이터 포인트는 버려지고 마지막(최근) 데이터 포인트 2개만 사용되므로 spike가 발생하더라도 놓칠 수 있다.
| time | 10 | 20 | 30 | 40 | 50 | 60 |
|---|---|---|---|---|---|---|
| metric value | 20 | 50 | 100 | 200 | 201 | 230 |
50초 시점에서(20초~50초 구간) 계산을 해보면
0.1 rps 밖에 안 되는데, 실제로 30초와 40초 사이의 변화율은 10 rps이고, 20초와 10초 사이의 변화율은 5 rps라는 점을 감안하면 0.1 rps는 너무 작은 값이다. 최대 rps가 순간변화율에 반영이 안 된 것이다.
¶ step의 변화에 너무 민감한 문제점
Grafana의 step값을 바꾸면 irate()의 결과가 크게 달라지는 경향이 있다. 아래 두 개의 차트는 동일한 시계열 지표 데이터에 대해 step만 달리 해서 irate()를 이용해 시각화한 것이다. 전혀 다른 차트로 보이지 않는가?
¶ step: 20m
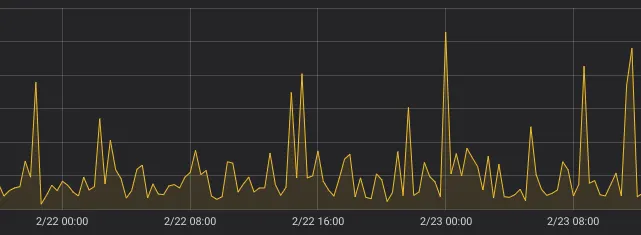
¶ step: 21m
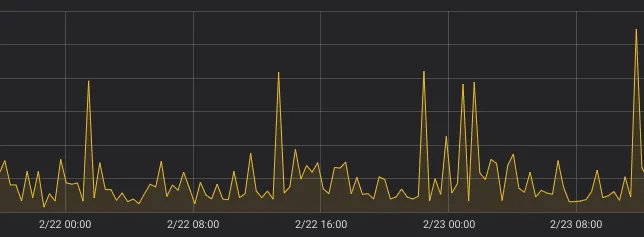
반면에 rate()는 step의 변화에 덜 민감한 경향을 보인다. 위 차트에 초록색 선으로 rate()를 추가해보면 다음과 같다.
¶ step: 20m
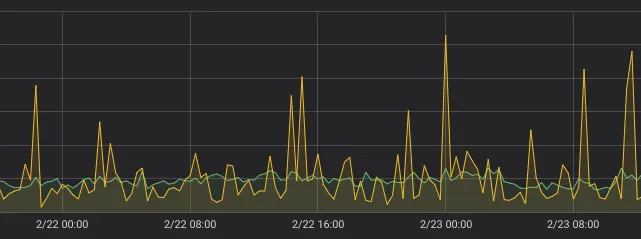
¶ step: 21m
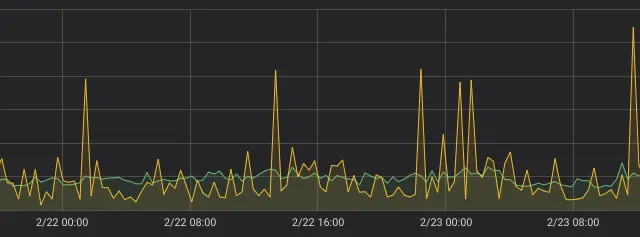
초록색 선으로 표시된 rate()를 증폭시켜서 본다면, rate()가 irate()보다 더 spike가 (상대적으로) 잘 드러나고 있고 본래 데이터의 경향이 잘 반영되고 있다는 것을 확인할 수 있다.
¶ 더 정교한 irate() 사용 방법
그러나 irate()를 아예 버릴 필요는 없다. 데이터 포인터를 좀 더 많이 사용하고, 변화율 값 중에서 최대값을 적극적으로 활용하면 약간 더 복잡하지만 spike를 잘 잡아내는 방법이 있다. 다음과 같이 irate()의 결과에 대해 max_over_time() 함수를 사용하는 방법이다.
max_over_time( ( irate( requests_count[45s] ) )[$__interval:10s] )
여기서는 수집 주기 $__interval이 15초라고 가정한다.
irate()를 실행할 때 45초 구간으로 잡고 2~3개 데이터 포인트를 사용하도록 설정함으로써 irate()가 필요로 하는 마지막(최근) 데이터 포인트 2개가 존재하도록 보장했고, max_over_time()을 실행할 때 $__interval값을 사용하거나 최소한 10초 이상이 되도록 보장했다.
10초 스텝은 의도적으로 수집 주기 15초보다 작게 잡아서, 더 촘촘하게 최대값을 구하려는 것이다.
순간변화율을 구할 때의 수집 구간과 max값을 구할 때의 수집 주기를 정교하게 제어함으로써 spike를 잘 감지할 수 있도록 할 수 있다.
¶ 변화량 increase()
번외로 increase는 변화율이 아니라 변화량을 추적할 때 사용한다.
일반적으로 increase()는 1시간부터 24시간 정도의 큰 시간 구간을 사용하고, rate()와 irate()는 5분 이하의 짧은 시간 구간을 사용하는 경향이 있다. 물론 짧은 시간 구간에 대해 변화량을 정확하게 추적하기 위해 increase()를 사용하는 것도 가능하지만, 지표의 변화에 대한 통찰력을 얻기 위해서는 변화량보다 변화율이 더 적절할 수 있음을 상기할 필요가 있다.
¶ 참고자료
- https://prometheus.io/docs/concepts/metric_types/
- https://opentelemetry.io/docs/specs/otel/metrics/data-model/#model-details
- https://techannotation.wordpress.com/2021/07/19/irate-vs-rate-whatre-they-telling-you/
- https://valyala.medium.com/why-irate-from-prometheus-doesnt-capture-spikes-45f9896d7832
- https://utcc.utoronto.ca/~cks/space/blog/sysadmin/PrometheusSubqueriesForSpikes